Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
Basic Information
- Pan Zhang1, Bo Zhang, Ting Zhang, Dong Chen, Yong Wang, Fang Wen @ University of Science and Technology of China, Microsoft Research Asia
- 2021 CVPR
問題描述
如同前面看過的 DACS,這一篇 paper 也是想要解決 semantic segmentation 當中 UDA(Unsupervised Domain Adaption) 的問題。
近年來流行 self-training 方法,透過 Pseudo Labelling 的方式來處理。也就是說會在訓練的過程當中透過當下的預測給這些 training data 一個假的 label,然後再拿去訓練。雖然這種做法開始能夠讓 source domain 適應 target domain 了,但比起 supervised learning 與 semi-supervised learning 的 performance 還是相差許多。
作者認為目前的做法存在兩個問題
只選擇信度高於某個閥值的預測作為 pseudo label,但結果不一定正確,會使模型被誤導 例如下圖,圈起來的
-就被錯誤分類。Image modified from Pan Zhang, Bo Zhang, Ting Zhang, Dong Chen, Yong Wang, Fang Wen (2021)
由於 Domain Gap 很大,Network 傾向在 target domain 上產生比較雜亂的特徵 就像是看到有殼的動物就當成是昆蟲,把四隻腳站立的動物都當成草食類動物一樣。認知跟實際充滿巨大的 Gap 導致對結果的特徵很雜亂。
針對上述兩個問題,作者分別使用 Online pseudo labels denoising 以及 learning a compact target structure 來解決。
Related Works
- UDA
- Unsupervised representation learning
- Learning from noisy labels
- Self-training
Methodology
Preliminary
這裡先定義一下接下來會用到的基本 Notation。
- 分別表示 source 和 target dataset 的大小
- 分別表示 source 和 target dataset
- 分別表示 source 和 target dataset 對應的 segmentation labels
- 表示 pseudo label
和 都有 個共通的 classes
Target
semantic segmentation 當中的 UDA 問題,目標在於給定 ,不知道 的前提下,去預測 target dataset 的 semantic segmentation。
其中一種方法是採用 Pseudo Labels,透過如 Cross Entropy Loss 來調整模型的機率分布。
其中 是一個 softmax probability 表示 pixel 是 class 的機率。 至於 則會直接表示屬於哪一個 class,也就是 hard labels。也額外定義 來轉換 soft 與 hard labels。
而一個 network 也可以拆成 feature extractor 以及 classifier 兩個部分,用 來表示。
Prototypical pseudo label denoising
作者認為每經過一個 training stage 才去更新 pseudo label 會太慢,在一個 training stage 當中 network 可能已經 overfit 在那些充滿噪點的 labels,被錯誤的資訊誤導了。
很直覺地,會想要讓 network 的參數更新、pseudo label 的更新 兩個可以同時處理。
然而,若直接同時更新的話,network 會很容易忽略了細部的特徵,進而傾向 overfit 在 source domain,只在 source domain 獲得高的分數。
因此作者提出的方法是將 soft pseudo labels 固定住,對於每個 class 選擇一個 prototype 以及一個對應的 weight 。訓練過程中根據與 prototype 之間的距離去調整 weight,進而影響預測的 pseudo label。
- 就是上述的 weight
- 與過去的 soft pseudo label 稍有不同,整個訓練過程中都會固定住
Tips
跟 Clustering 頗類似,每個 cluster 的中心點就如同這裡的 prototype,距離 cluster A 中心點越近,模型就越相信他是屬於 cluster A。
我們會隨著訓練過程慢慢調整 prototype,讓他越來越貼合真實的狀況。
Image from Pan Zhang, Bo Zhang, Ting Zhang, Dong Chen, Yong Wang, Fang Wen (2021)
當然,這裡的距離是投射到高維空間之後 feature 之間的距離!
權重計算
權重的計算方式如下
- 表示第 筆 target data 的 feature
- 是 momentum encoder,可以看成是更新較慢的 encoder
- 表示 class 的特徵中心點
- 表示 softmax temperature,這裡設為
權重的計算方式本質上就是 softmax function。計算的是 feature 跟每個 class 的中心點 距離遠近。
- 當距離很大時,產出的權重就會很小
- 當距離很小時,產出的權重就會很大
prototype 計算
而 prototype 的計算方式如下
Prototype 的計算本質上就是找中心點。把所有對應到 class 的 feature 加總後平均。
然而這種做法每次要更新 prototype 就需要看過整個 target dataset 的所有 features,計算上負擔過大。因此作者改用一個 mini-batch 當中中心點的 moving average 來估計 (Exponential Moving Average, EMA)。
- 表示當前 mini-batch 當中 class 的 feature 平均
Loss 計算
至此我們有了新的方法取得 pseudo labels (也就是 ),最後就剩下更新的 Loss 如何計算。
與傳統的 Cross Entropy(CE) 不同,這裡作者採用 Symmetric Cross Entropy(SCE) 試圖增加對 lebel noise 的容忍程度。
Tips
改成透過 prototype 去調整 pseudo label 能夠帶來許多的好處
- 對 outlier 比較不敏感
- 每個 class 都是平等的,較不會因為 class 的不平衡導致預測錯誤
- 在 semantic segmentation 中這一點尤其重要,因為 class 的分布往往分散
- 實際上對於 hard class 的預測有改善
- 對於一開始預測錯誤的 pseudo labels 能夠漸漸改正
Structure learning by enforcing consistency
理想上,只要我們的 feature extractor 能好好表示出 feature,即便在 target domain 上也能好好地區分不同的 class,那麼 pseudo label 也就可以更好地減輕 noise 的影響。
然而因為 Domain Adaption 尤其 UDA 對於 target domain 的認識嚴重缺乏,encode 出來的 features 往往會很分散。
作者透過對所擁有的 target domain 知識增強來改善,並且分成了弱增強 以及 強增強 。實際上,弱增強只是給原圖,強增強只是加上 data augumentation。
這裡使用的 Data Augumentation 包含了旋轉、明暗調整、彩度調整等
我們的目標是要讓 與 對應的 feature 可以比較接近。作者分別去計算兩者的 weight 與 (稱為 Soft prototypical assignment),試圖讓他們產出的分布要越接近越好。因此透過 KL divergence 去計算 loss 。
其中
兩者差異只在於使用的 encoder 分別是 和 。因為 是由弱增強得到,受到的干擾較少,因此適合用來教 encoder 經過強增強的 prototype assignment 應該與經過弱增強的相同。
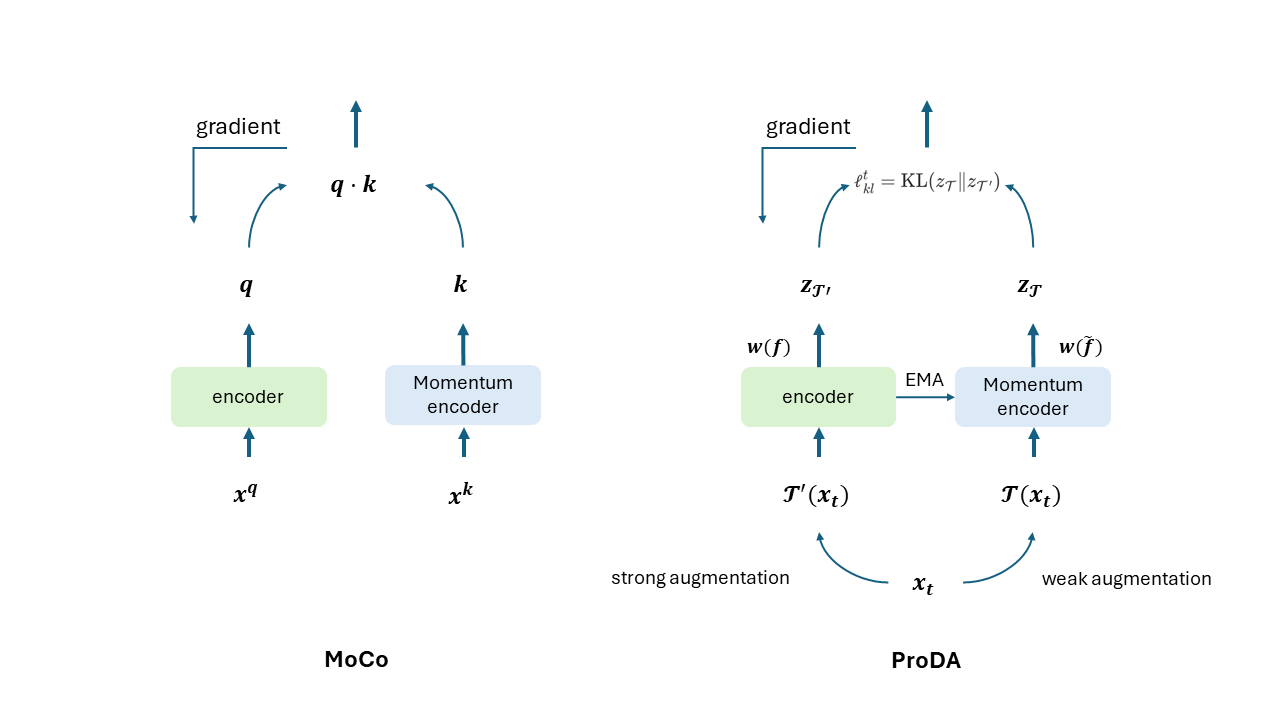
Tips
如此一來,就能夠迫使模型對於這些略有不同的 feature 具有相同的 pseudo label,使得 target domain features 更加密集。
最後,為了避免所謂的 degeneration issue,也就是有些 cluster 是空的狀態,作者進一步設計一個 loss 鼓勵類別盡量地平均。
將上述的種種 loss 結合,合併成底下的 loss 。
Distillation to self-supervised model
最後,作者進一步加上了 Knowledge Distillation,使最終的結果進一步提昇。
- 透過前面的步驟得到的模型稱為 ,會做為 KD 當中的 Teacher Model。
- 要訓練的 Student Model 稱為 。會採用 SimCLRv2 的 pretrain weights 開始訓練。
為了避免 student model 忘記 source domain 的知識,所以也會把 source domain 的資料拿進來使用。整體的 Loss 計算方式如下。
整體流程
整體流程被分成三個階段。
第一階段包含了 Prototypical Pseudo Label Denoising 以及 Target Structure Learning。 目的是要先訓練出一個 Teacher Model。意即讓 收斂。
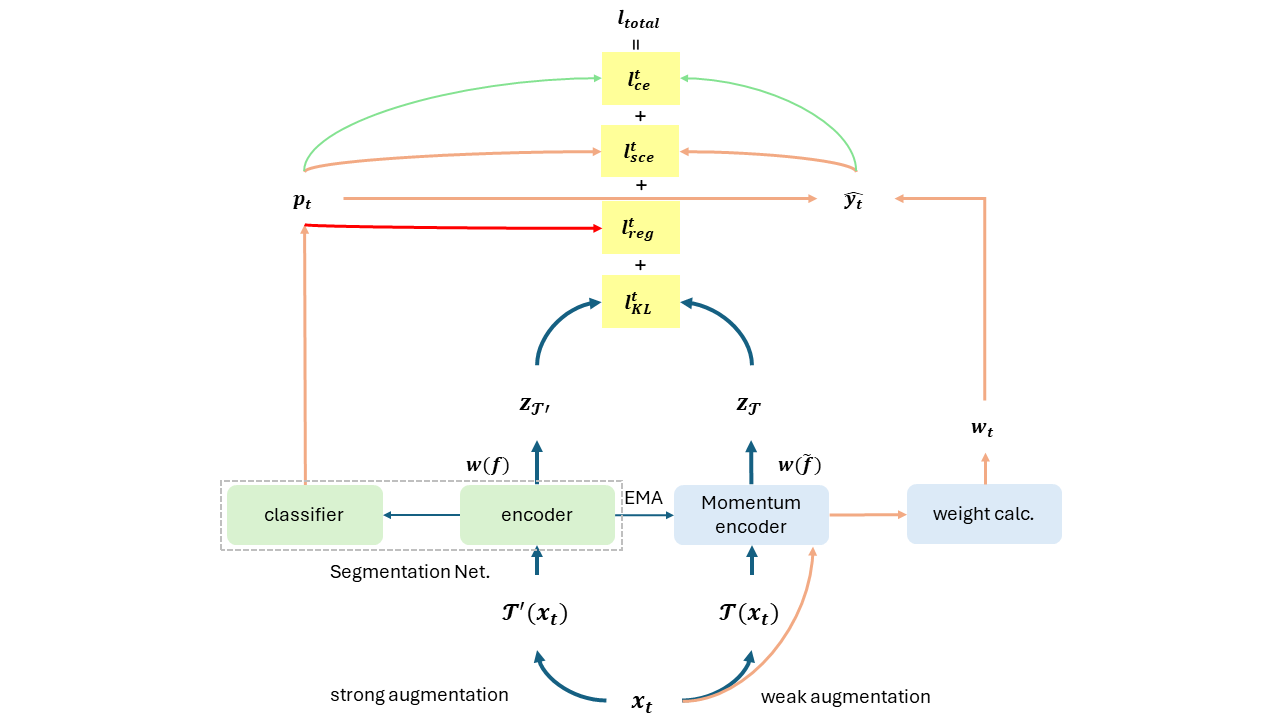
ProDA_Losses 第二與第三階段都是 Knowledge Distillation。 目的是要訓練出一個 Student Model。意即讓 收斂。
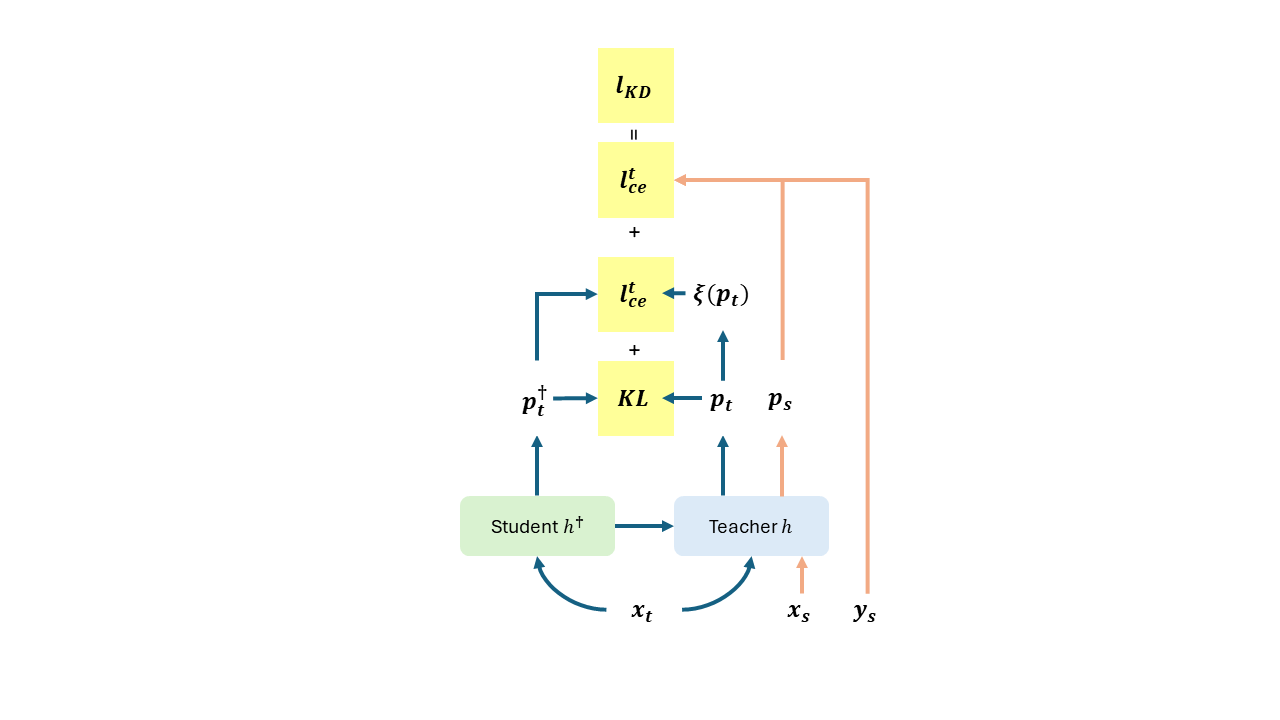
ProDA_Losses2
Caution
根據 Appendix 附上的 algorithm,實際上他所謂的 避免模型忘記 source domain 只不過是把 source data 扔進 "teacher model",取得 ,然後拿去 tune "student model"。
但是從頭到尾都沒丟給 student model,為甚麼可以直接拿去 tune,並且預期能夠讓 student model "學會 source domain" 的資料?
Results
實驗設定
Segmentation 模型採用 DeepLabv2 搭配 ResNet-101 Backbone。
訓練前首先透過 AdaptSegNet 搭配對抗式學習對 segmentation 模型 warmup。
Knowledge Distillation 的部分採用了 pretrained SimCLRv2 搭配 ResNet-101 backbone。
Dataset 的部分一如既往採用 GTA5、SYNTHIA、Cityscapes 這三個 datasets。之前在 DACS 也有介紹過同樣的 datasets。
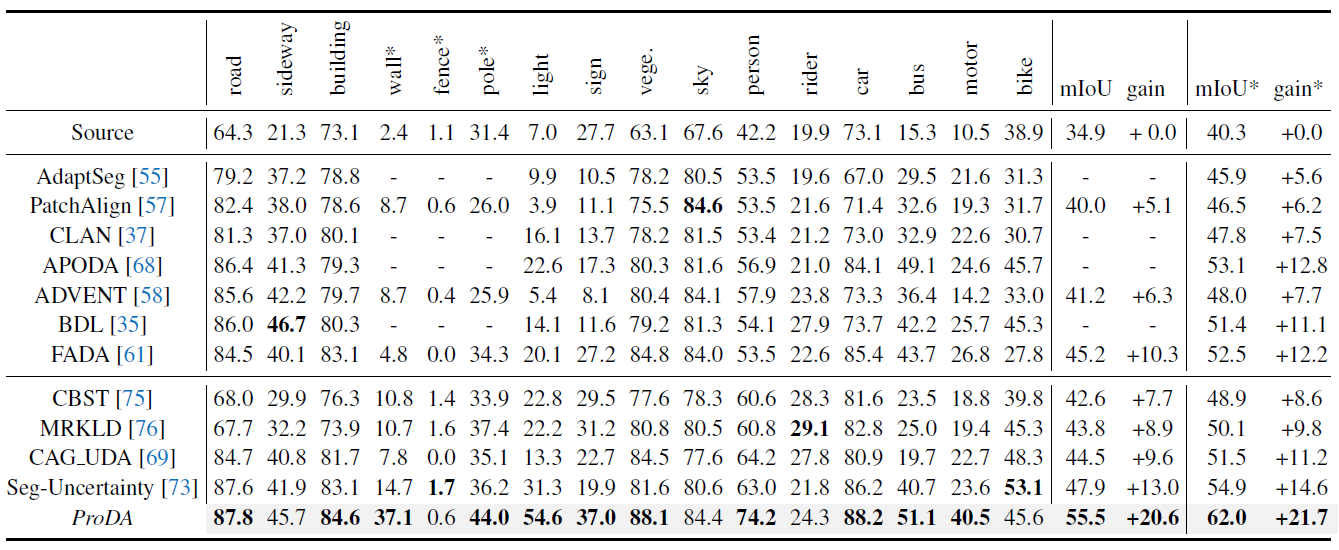
接下來直接看 ProDA 在兩個 benchmarks 上面的表現。
GTA5 Cityscapes
在 GTA5 Cityscapes 的部分明顯可以看到最後的 mIOU 比起過去的 SOTA models 好許多。在絕大多數的類別當中也是比起過去的做法還要強。
這樣的進步有蠻多部分是來自於對較難分類的類別的提升。因為我們現在對每一個 classes 都是平等對待所導致。
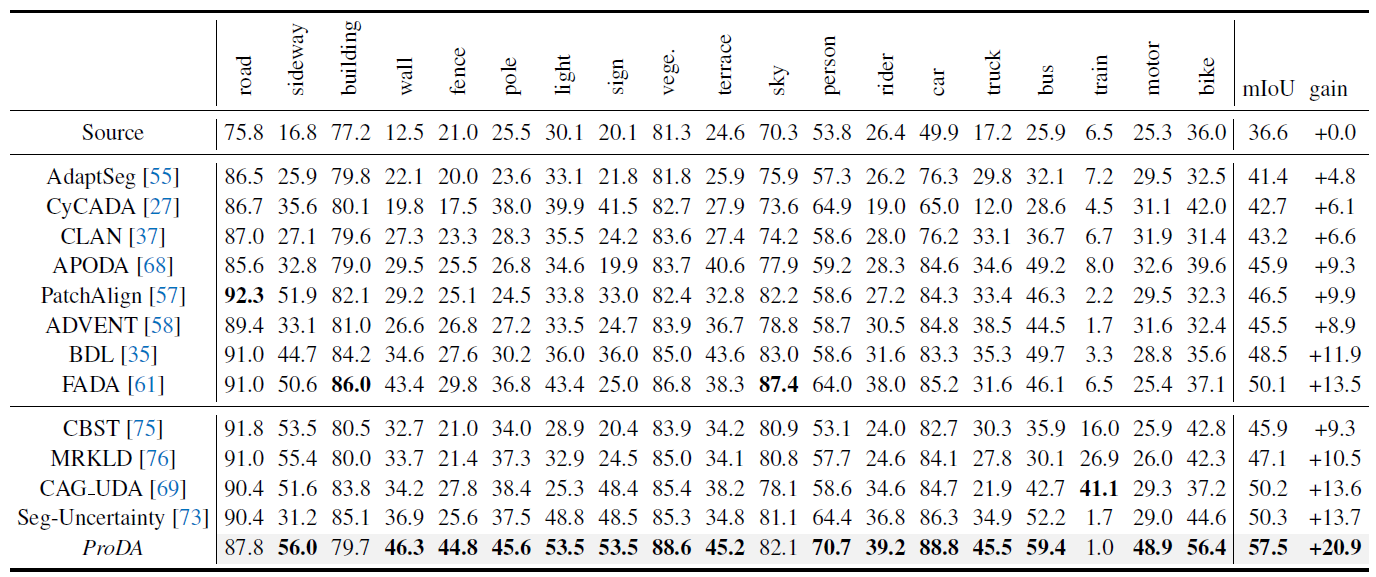
Image from Pan Zhang, Bo Zhang, Ting Zhang, Dong Chen, Yong Wang, Fang Wen (2021)
上半部分是用 domain alignment 的解決方案,下面則是 self-training。
SYNTHIA Cityscapes
在 SYNTHIA Cityscapes 的部分如下,同樣可以看到 mIoU 比起過去的 SOTA 有不少的提升。
Contribution
- 提出一個可以即時修正 psuedo label 的方法(prototypes)
- 展示知識蒸餾(Knowledge Distillation)在 UDA 上同樣可以獲得更多改善
- 提出一個新的 UDA for semantic segmentation 的 SOTA model ProDA
值得一看的文章們
- [論文筆記]Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
- UDA 論文 HackMD 筆記
- 剖析深度學習 (2):你知道Cross Entropy和KL Divergence代表什麼意義嗎?談機器學習裡的資訊理論
- 【读】领域自适应语义分割 - ProDA
- 論文筆記 — Momentum Contrast for Unsupervised Visual Representation Learning(MOCO)
- Momentum Contrast for Unsupervised Visual Representation Learning
- Symmetric Cross Entropy