PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
Basic Information
- Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua
- 2022 ACM Multimedia
問題描述
這一篇與過去看過的 DACS, ProDA, DAFormer, HRDA 同樣都是以 Unsupervised 的方式解決 Semantic Segmentationb 的 Domain Adaptation問題。
也就是說,我們會在一個 Source Domain 上具有標記過的資料,但是 Target Domain 上則缺乏標記。我們的目標是透過這些資料去學習,讓這個模型有辦法對 Target Domain 上的資料順利地給予正確的 Label。
過去的這些 Works 普遍關注於如何在不同 Domain 之間築起橋梁,讓他們的 Domain Gaps 減少。包含了在 pixel level, feature level 以及 prediction level 之間的 Domain Gaps。
然而,這卻忽略了在同一個 Domain 當中的特徵。
Info
這就好比我們學會對應 Source Domain 當中的"汽車"如何對應到 Target Domain,卻不太了解同樣 Source Domain 當中同樣是"汽車"的部份有怎樣的關聯。
作者提出 PiPa,一個 Pixel-wise 以及 Patch-wise 的 self-supervised 的架構,能夠應用在過去的各種 UDA for semantic segmentation 問題上,並超越過去的 SOTA。
Related Works
- Unsupervised Domain Adaptation (UDA)
- Contrastive Learning
Methodology
大致分成了三個主軸
- 基本的 UDA Loss 設定
- Pixel-wise Contrastive Learning
- Patch-wise Contrastive Learning
最後再將這三個部份結合起來。
基本的 UDA Loss 設定
與過往我們讀過的幾篇論文一樣,我們會先設定好最基本的兩組 Loss。分別會希望我們的模型在 Source Domain 以及 Target Domain 的預測結果要與對應的 Label 相同。
對於 Target Domain,因為缺少了 Label 標記,因此會使用 Pseudo Label。
也與過去的做法相同,會加上知識蒸餾(Knowledge Distillation, KD),因此會包含了 Student Network 以及 Teacher Network。
其中的一些 Notations:
- 表示 Source Domain,包含了 個資料。
- 表示 Target Domain,包含了 個資料。
- 表示在 Source Domain 的第 個資料。而 是對應的 Label。
- 表示在 Target Domain 的第 個資料。
- 是 轉換成 one-hot 的形式。
- 是預測的 pseudo label 轉換成 one-hot 的形式。
- 是我們的模型 backbone。對應的 teacher network 為 。
- 是最終給出 label 的 network。
針對 Target Domain 的 Loss,作者提及因為 Domain Gap 的存在,導致 pseudo label 必然會存在 noise。也就意味著並不是所有的 pseudo label 都值得信任。
因此 計算上只會考慮 大於某個 threshold 的部份。意即只有那些足以信任的預測結果才會被考慮進去。
此外,也如同 DAFormer 與 DACS,他們會對 Source Domain 與 Target Domain 的圖片去做混合,得到相對應的圖片 與 Pseudo Label ,當然也有對應的 one-hot vector 。因此 被改寫如下。
Pixel-wise Contrastive Learning
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
Pixel-wise 的想法就是希望具有相同 Class 的 Pixel 要有類似的 Feature,反之則要有較為不同的 Feature。如上圖,同樣是圓圈的部份會被拉進,不同的則被推遠。
實際上的做法是把 產出的 feature 經過 Projection Head 得到對應的 Feature Map 。接著透過 Contrastive Learning 去把應該要相近的 feature 拉近,反之推遠。
定義 Loss 如下。
其中
- 表示 Feature Map 的第 個特徵。也就是 pixel 對應的特徵。
- 表示 pixel 對應的 class。
- 用來描述 與 的相似性。採用的是 Exponential Cosine Similarity。
其中 表示 cosine similarity。
由於這裡需要 class 的資訊,因此只會使用到 Source Domain 的資料。
Patch-wise Contrastive Learning
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
Patch-wise 的想法是今天同一個 crop 無論是出現在 patch 的右上角還是 patch 的左下角,因為同樣都是對應到相同的 crop,所以特徵也必須要相同。
作法上會把 Mixed Image 經過 Projection Head 後,從當中切出兩個大小相同的 Patch ,並且他們之間有一個重疊的區塊 。目標是要讓同樣都在 的特徵拉近,否則推遠。
定義 Loss 如下。
其中
- 表示 pixel 經過 得到對應的特徵。
- 與 Pixel-wise 一樣表示 Exponential Cosine Similarity。
結合
最後結合上面三個部分,可以得到最終的 Loss 如下。
整體的架構可以用底下這張圖來簡單了解。
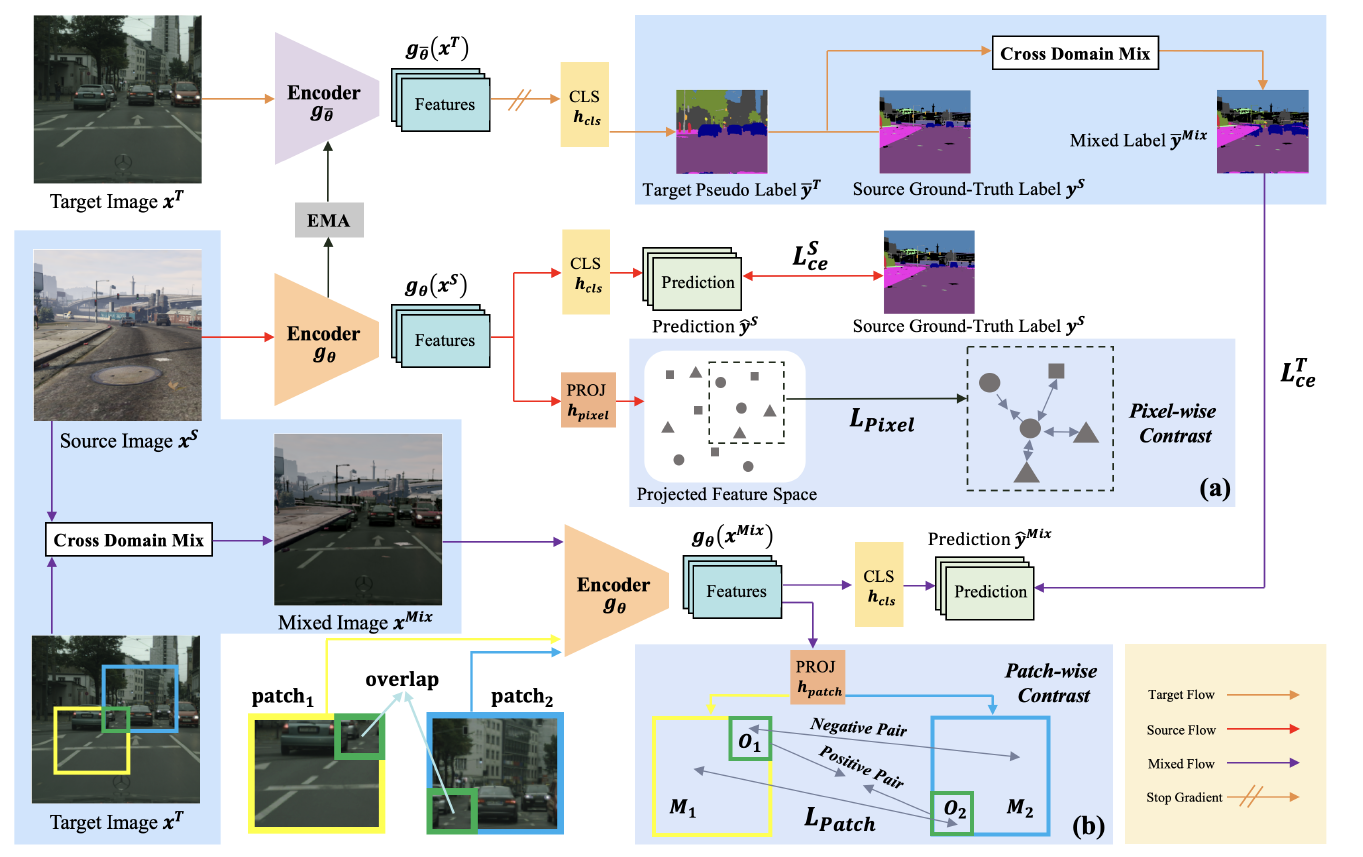
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
由於 Pixel-wise Consistency 與 Patch-wise Consistency 都是在幫助訓練,因此在測試階段的時候這兩個部分是不會參與的。上圖當中的藍色區塊都是只在訓練階段包含的架構。
Results
實驗設定
與過去相同,我們一樣會有 GTA5, Cityscapes, SYNTHIA 這三個 datasets,測試 (1) GTA5 Cityscapes 以及 (2) SYNTHIA Cityscapes 的結果。
實作上採用了常見的 mmsegmentation framework,Network 的架構由於 PiPa 的通用性,作者有在 DAFormer 以及 HRDA 分別搭配 PiPa 去做實驗。
Quantitative Comparison
首先看到 GTA5 Cityscapes 的結果。
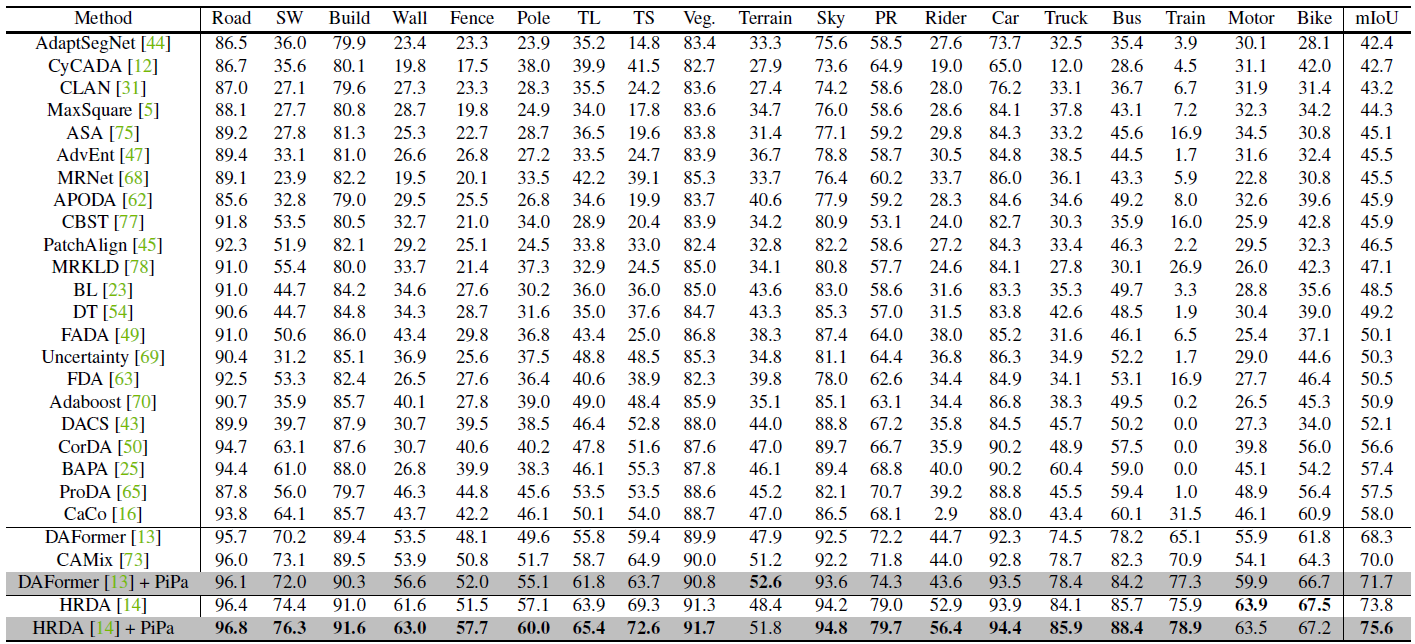
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
可以看到無論是把 PiPa 搭配 DAFormer 或是 HRDA 都可以進一步得到更好的最終結果。而對於細部每一個預測的 Class 則可以看到在絕大多數的類別都有了提升。
接下來看到 SYNTHIA Cityscapes 的結果。
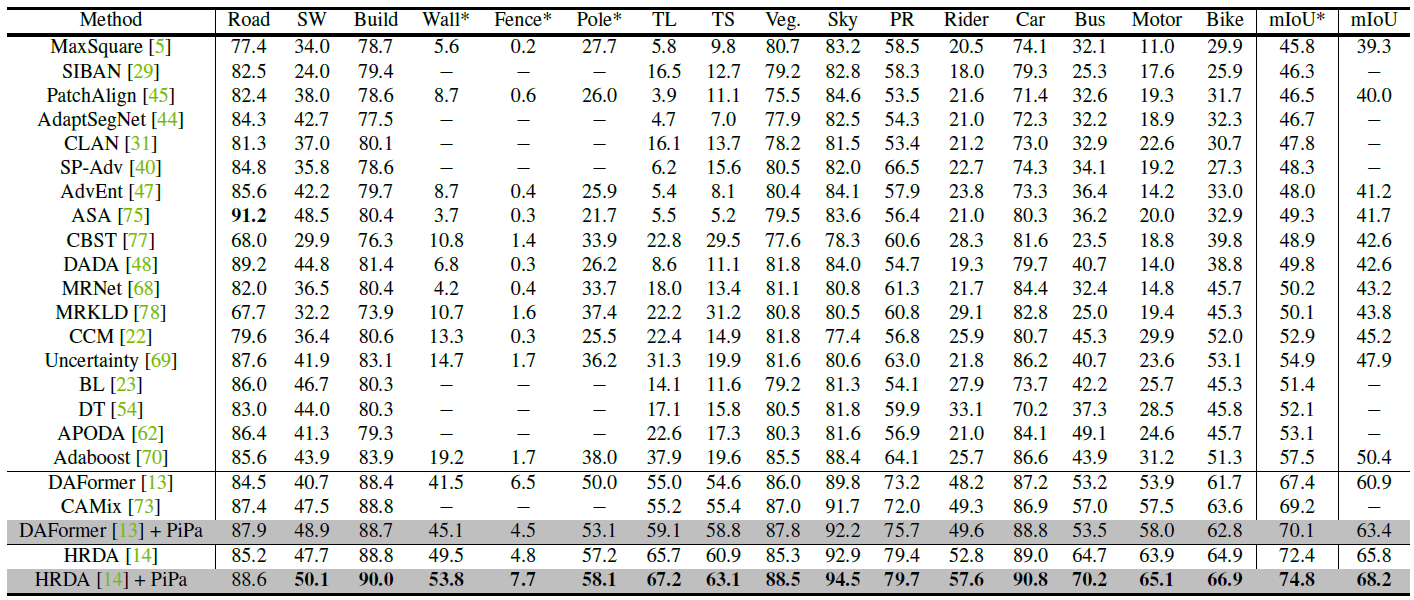
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
同樣也可以看到與 GTA5 Cityscapes 相同的結果。
Tips
與 HRDA + MIC 相較之下,HRDA + PiPa 在 GTA5 Cityscapes 小輸 0.3 mIoU,而 SYNTHIA Cityscapes 則大贏 7.5 mIoU。
Info
SYNTHIA 這個 Dataset 因為部分 paper 採用 16 個 classes,部分則是 13 個 classes 的資料去訓練,因此在數據上 mIoU 有兩列分別表示 16 個平均跟 13 個的平均。
Qualitative Results
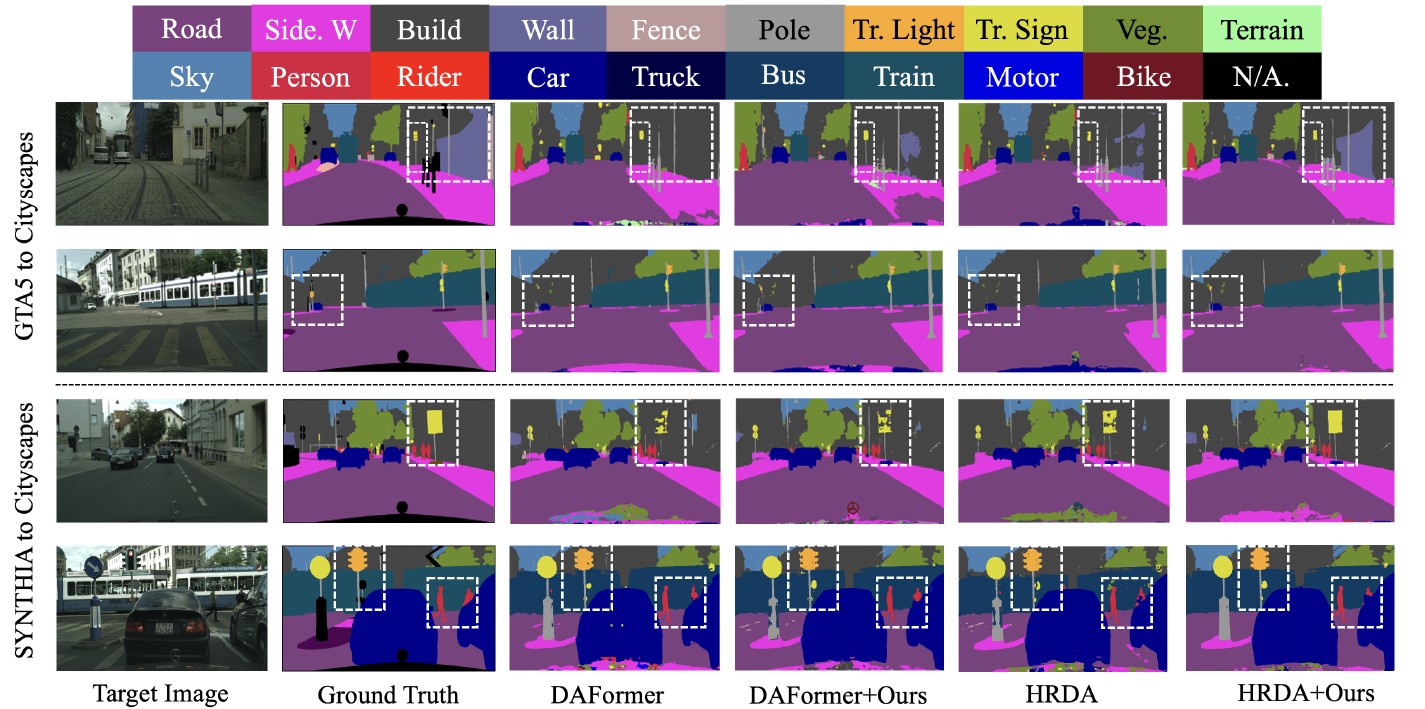
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
從圖片上的結果可以看到結果有了一些提升,主要是在細節的呈現上更精準了。
Ablation Studies
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
針對 GTA5 Cisyscapes 的部份作者嘗試了解 Patch Contrast 與 Pixel Contrast 分別帶來的效益。可以看到兩者分別使最後結果提升了 1.4 mIoU 與 2.3 mIoU,並且兩者結合後可以再帶來更高的 3.3 mIoU 的提升。
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
針對 與 的選擇上,作者認為 PiPa 比較不會對 hyperparameter 敏感。在實驗的幾組 都會帶來相近的結果,並且都比 baseline DAFormer 的 68.4 來得高。
Image from Mu Chen, Zhedong Zheng, Yi Yang, Tat-Seng Chua (2022)
最後,針對 Patch-wise 得 Crop Size,作者認為普遍來說 Crop Size 是越高越好,不過實驗中 720x720 的大小會是最恰當的。當 Crop Size 過大時,會時常導致 Overlapped 的區域過大,因此也不太適合將 Crop Size 社得太大。
Contribution
- 針對 intra-domain knowledge 去改善 UDA 的成果
- 設計出一個通用的架構
- 在 GTA5 Cityscapes 與 SYNTHIA Cityscapes 與 HRDA 結合後分別得到 75.6 與 68.2 mIoU